在iOS、macOS上全速虚拟化Linux用户态

用两周的时间做了一个iOS和macOS上的轻量级Linux“虚拟机”,不需要虚拟化Hypervisor支持,不需要内核支持,可以直接给你一个Linux shell,里面运行原生ARM64的Linux程序。
由于采用了即时编译(Just-In-Time compilation, JIT)技术,它的性能损失很小,在计算密集型任务里,比硬件虚拟化慢10~20%,比解释执行快接近10倍。
它主要包含两部分,前端是一个基于iSH和iSH-arm64的Linux兼容层(用C实现),后端是一个arm64-to-arm64 JIT解释器(用C和汇编实现)。
- Linux兼容层用一个Darwin线程模拟一个Linux线程,在用户态模拟页表、TLB等结构,并接管和仿真系统调用。
- JIT解释器将Linux binary的代码段即时转译成原生arm64代码,映射其中的寄存器为主机端寄存器,把访存指令转译成对TLB的访问,把缺页中断和系统调用中断转接给Linux兼容层,设置可执行位并跳转执行。
跑个分
使用sysbench cpu run在Apple M4上测试结果如下。
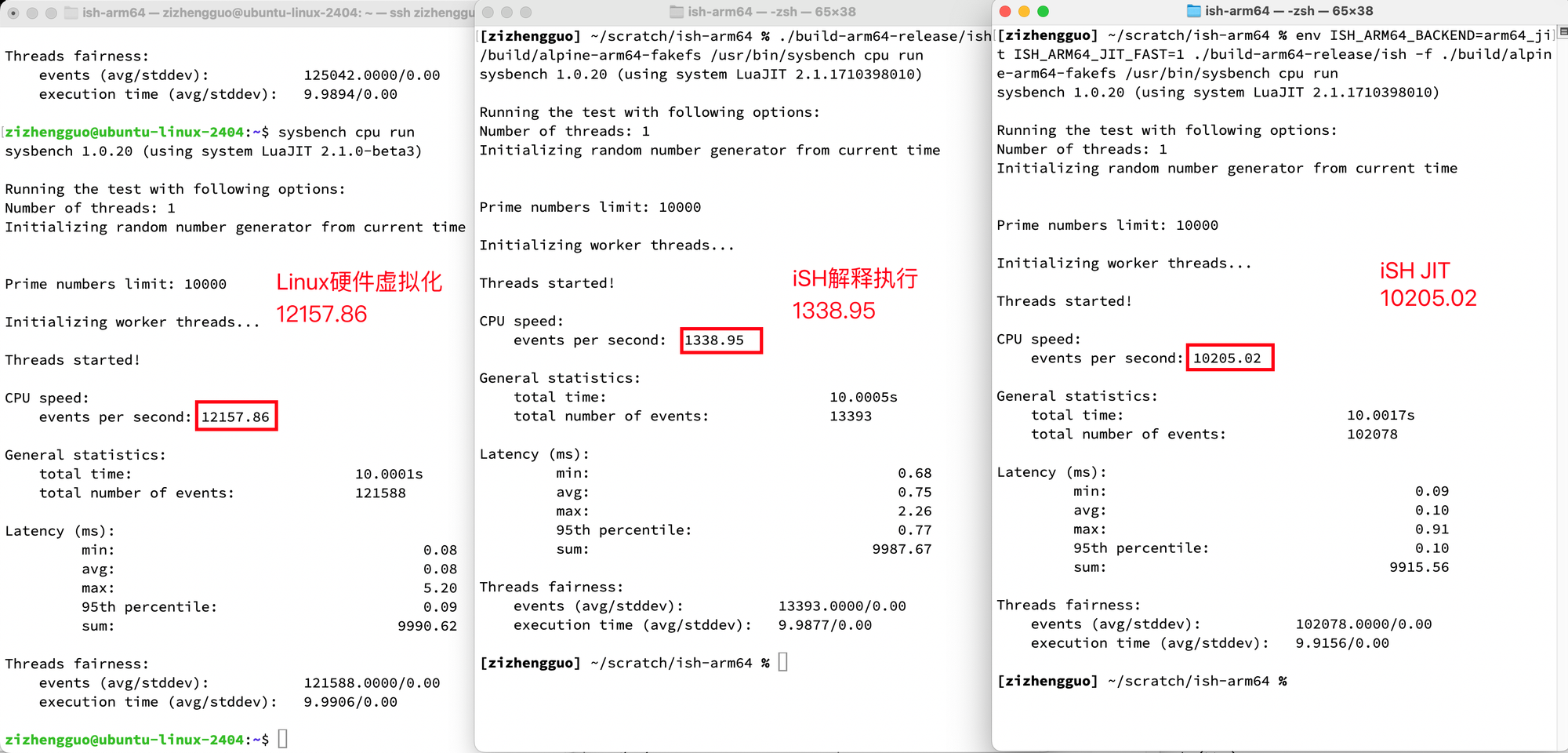
在Apple A16 (iPhone 14 Pro, iOS 17.0)上测试结果如下。

碎碎念
JIT解释器一般都是相当复杂的计算机工程,这方面做到极致的就是现代浏览器内核里的高效Javascript引擎如v8、SpiderMonkey和JavascriptCore。JIT的思想是非常强大的,理论上它可以让任何代码逻辑在任何硬件上全速运行,弥补架构和软件层面的限制。比如,iPhone上只能运行封闭的iOS系统,但其实它拥有非常强大的CPU,完全可以做很多超出它体积想象力的事。
因此出于玩一玩/领略计算机科学魅力/学习/说不定将来有点用处……的目的(摸鱼理由),我花了两周的时间push GPT 5.5实现了一个最简单的arm64-to-arm64 JIT解释器。由于不存在ISA层面的翻译,其实省却了不少麻烦,但是想要达到接近满速,还是需要在设计JIT引擎时对两个操作系统和arm64 ISA有一定的了解。
vibe coding感想碎碎念:早就想这么玩了😝 这个idea躺在我的笔记里很久了,但是在AI agent变好用以前,这个东西的工期我预计至少要6个月起步,对我来说拿出完整6个月的时间折腾一个没啥用的项目过于奢侈,而且这种东西写起来肯定比想象的麻烦很多(事实确实如此),写两个月遇到一堆bug肯定就力竭了。
反观如今的AI agent,已经强大到自己开始猛猛写浏览器内核、编译器了,然而这两件任务完成的都差强人意,在知乎上被喷惨(1, 2)。cursor的浏览器内核让agent花了一周的时间,被疯狂reward hack:JS内核、CSS layout、HTML parser全是调库没有一个是自己写的;而anthropic的编译器跑了两周,结果编译出来的程序比gcc不开优化跑得还慢。就目前而言,这或许是没有人类指导的情况下agentic loop的极限所在,再过几个月是什么样还不好说。
这次这个项目我用了大约$1000刀的GPT 5.5 High Token,在Codex里vibe出来的。它明显比之前尝试过的vibe overleaf项目复杂得多,不仅工期和Token消耗翻倍,而且个人体感也更累了,被迫快乐地复习了一遍ICS。这次不能再像上次那样一行代码都不看,因为agent在处理困难任务的时候非常容易退而求其次糊弄了事,我们自己需要知道自己想要什么,才能push AI帮我们解决问题。
架构心得
我其实一开始并不会写JIT解释器。但是在跟AI互动过程中,看AI犯各种错误,我开始慢慢get到了JIT解释器应该是什么样子,在前两天推倒重来了几次,终于走上道了。以下是站在全部写完的视角,事后诸葛亮回看整个架构设计的样子。
想要让即时编译代码跑得快,我们需要尽量把原生指令映射到原生指令,尽最大努力减少跳出到外层解释器的次数。为此我们构建一个心智模型:
对于纯计算类型的指令,如add x4, x2, #0xa28,我们希望它JIT过后还是一样的计算指令。尤其是对于复杂耗时的浮点指令如fdiv d0, d1, d0更是如此。这些指令的操作数都在寄存器里,而arm64下的寄存器主要是通用寄存器GPR (x0-x31)和浮点/向量寄存器Neon register两种。针对通用寄存器,我们需要用其中一部分持有对JIT运行时结构的指针,因此我们并不能做到GPR对GPR的一一映射,必须要做一个常用寄存器的重排,也就是说,即使是相同ISA的JIT编译器,也需要做寄存器分配。而Neon register我们可以让JIT运行时不要去触碰它们(而这又涉及到了ABI的问题)。
对于访存类型的指令,如ldr x3, [x0, #8],由于页表是虚拟的,这些都需要交给Linux兼容层来处理。我想过能否在Darwin内核下直接映射到相同的地址,可惜两个内核的用户空间地址范围并不兼容,而且甚至页表大小都不一样(16K vs 4K),只能作罢。访存类型的指令是非常密集的,我们必须引起绝对的重视。我们维护一个软件模拟的TLB缓存,作为软件模拟缓存,它必须是直接映射的。事实上TLB能够满足99%以上的访存请求。我们把TLB访存的过程用汇编实现,而TLB miss的情况则fallback到Linux兼容层。
事实上,除了访存以外,我们还有非常多用汇编实现的JIT helper和inline snippet。为啥不用C?除了这一小段代码的效率,更重要的是,C的函数调用约束将大量的寄存器设为调用者保存寄存器,包含一半的GPR,和全部的Neon register,我们每次在JIT代码里调用C runtime都需要把所有这些寄存器值存进内存结构里,调用完以后再全部取出来,这个性能损失是我们绝对不能接受的。因此我们需要设计一个JIT helper ABI,它针对最常见操作的hot path,如检查TLB hit等任务,仅使用我们为其分配的固定7个寄存器(x0-x3, x16-x17, x30)完成,螺蛳壳里做道场。我们留下18个GPR用做映射使用:x4-x15, x19-x29。把控制和状态寄存器NZCV, FPCR, FPSR全部交给JIT代码支配。使用几个固定寄存器保存运行时状态:x19保存cpu状态的struct,x20保存tlb,x21保存runtime指针,x22保存JIT用户态的栈指针SP。栈寄存器和PC是无法完美映射的,必须特殊处理。
对于跳转类型的指令,主要有固定地址跳转B(以及它的条件跳转版本)、间接跳转BR,RET、函数调用BL,BLR这几种类型。固定地址跳转是需要重点优化的,因为它通常在高性能计算代码里用来实现循环。我们设计了一个代码分段扫描器,用一些heuristic识别出函数的边界,确保一个函数被划分在一个JIT fragment里。在JIT fragment内部的固定地址跳转,我们可以通过计算JIT后代码的相对偏移,把它完美映射成相同的指令。这里用于识别函数边界的heuristic可以看做非常简单的数据流分析。
而间接跳转的优化则要复杂很多。这种类型的指令需要从寄存器里取跳转的目标地址。这里有两个问题。
- 如何找到目标地址对应的JIT fragment?这其实是一个数据结构卡常数问题。我们在页表和TLB里记录了每个代码页已经编译好的JIT fragment映射关系,这样就可以从中获得特定目标代码地址对应的fragment和它编译后的代码偏移量。然而,这个性能是不过关的。经过多次测试,我们设计了一个两级的JIT目标地址解析缓存。L2是一个用页表id做key的两路组相联cache,它用做同一代码段内多个跳转目标的冷启动;L1是一个用PC尾部bit做key的直接映射cache,专门用来防止仅有L2的时候两路组相联不够用的情况,因为我观察到有些workload里一个循环里需要在一个代码页中三处以上fragment里跳来跳去,而这些fragment本身的寄存器需求数导致它们无法相互合并。
- 如何快速跳转到目标地址?和访存阶段的设计一样,我们不能接受每次交给C runtime,这样会导致所有Neon寄存器被读写一遍。实际上,我们只需要把两边分别映射的GPR做初始化就好了。我们针对每个fragment额外写出两段JIT辅助函数,一段负责存它的GPR,一段负责取它的GPR,这样需要从fragment A跳转到fragment B时,只需要调用A的存函数和B的取函数就可以。这些函数同理也都必须是JIT ABI汇编。
以上对间接跳转的优化,是在不做复杂的数据流分析情况下的极限。然而,想要在sysbench里取得接近原生运行的效率,确实是需要做高级一点的数据流分析和优化的。这是因为sysbench cpu的prime循环里,调用了fsqrt,而fsqrt是一个动态链接的函数,调用它需要走PLT,这是一个间接跳转,然后返回来要用ret,又是一个间接跳转。至此,我们终于稍微窥探了一丢丢真正的JIT编译器克苏鲁了,那就是分级投机JIT优化。现代JIT引擎会针对同一段代码生成多种不同的JIT代码,比如JavascriptCore就分成了整整三级 : baseline JIT, DFG JIT, FTL JIT。从前往后,生成代码的质量越来越高,而代价也越来越高。JIT引擎会从baseline JIT开始,一边运行,一边做动态的性能监测,假如发现一段代码被频繁调用,则会把那段代码重新用更高一级的JIT编译一遍。
借鉴这个思想,我们做了一个针对间接跳转和函数调用/返回特殊优化的fast JIT,它在我们的baseline JIT基础上,通过一个类似投机CPU里的返回地址栈RAS优化的机制,计数每一层函数调用在间接跳转上花的代价。针对优化价值高的函数,将其用fast JIT重新转译一遍。fast JIT会内联所有函数调用,会把形如PLT的间接函数调用尝试改写为固定地址,如果运行时间接调用的地址发生变化则会自动fallback到slow JIT。针对真正的PLT,目标地址写了就一般不会变了,这就非常有用。有了它以后,我们终于在sysbench上达到了如上的效果。在优化之前,sysbench基本只有一半左右的性能。
试试看
你可以在gzz2000/ish-jit-arm64下载到源代码,使用以下命令编译macOS版:
git submodule update --init --recursive
meson setup build-arm64-release -Dguest_arch=arm64 --buildtype=release
ninja -C build-arm64-release
然后根据README指引,构建一个alpine rootfs。然后使用
env ISH_ARM64_BACKEND=arm64_jit ISH_ARM64_JIT_FAST=1 ./build-arm64-release/ish -f ./build/alpine-arm64-fakefs /bin/sh
启动一个shell。
使用以下命令可以编译iOS程序包.tipa:
./tools/package_arm64_trollstore_ipa.sh
编译得到build/iSH-ARM64-JIT-TrollStore.tipa。
由于库克在iOS系统里限制了JIT权限,必须采用特殊的手段才可以运行。假如你的iOS版本低于17.0,则可以安装TrollStore并使用TrollStore侧载以上的.tipa安装包。此安装包含有一系列特殊的沙盒绕过权限标记,不可以用普通的侧载方式(如AltStore, SideStore, LiveContainer等)安装。
假如你的iOS版本较高,仍然可以使用,但是会复杂一些,请你尝试把这段话发给你的ai agent:“我需要把iSH-jit-arm64侧载安装在高版本的iOS系统上,目标系统不支持TrollStore,请你为它换一种JIT的实现方式,参考https://github.com/AngelAuraMC/Amethyst-iOS,将iSH-jit-arm64重新编译成标准ipa安装包,仅允许get-task-allow这一entitlement。使用StikDebug/StikJIT/AltJIT方案,告诉我怎么做。”
have fun!